
找到个不错的听歌网站,爬虫安排上
比较简单的一个爬虫
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import os
def Menu(key):
global dic
url = f"https://www.gequbao.com/s/{key}"
response = requests.get(url, headers=headers).text
soup = BeautifulSoup(response, "lxml")
song_list = soup.find_all("div", class_="row")
count = len(song_list)
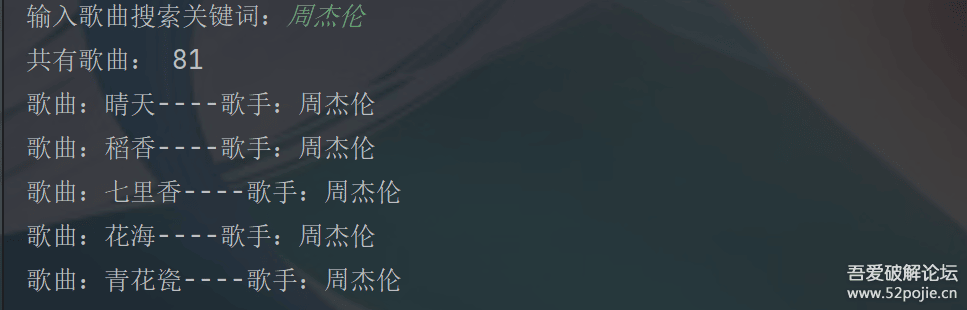
print("共有歌曲:", count - 2)
for i in song_list[1:count - 1]:
song_name = i.find("div", class_='col-5').find("a").text.replace("\n", "").replace("\r", "").replace(" ", "")
singer_name = i.find("div", class_='col-4').text.replace("\n", "").replace("\r", "").replace(" ", "")
url = i.find("div", class_='col-3').find("a").get("href")
down_url = 'https://www.gequbao.com' + url
dic[song_name] = down_url
print(f"歌曲:{song_name}----歌手:{singer_name}")
def Download(song_name):
url = dic[song_name]
id= url.split('/')[4]
data_url=f'https://www.gequbao.com/api/play_url?id={id}&json=1'
response = requests.get(data_url, headers=headers).json()
sava_url = response['data']['url']
sava(sava_url, song_name)
def sava(song_down, song_name):
if not os.path.exists("./歌曲"):
os.mkdir("./歌曲")
response = requests.get(song_down, headers=headers).content
with open(f"./歌曲/{song_name}.mp3", "wb") as f:
f.write(response)
print("下载成功")
if __name__ == '__main__':
key = input("输入歌曲搜索关键词:")
ua = UserAgent().random
headers = {
"User-Agent": ua
}
dic = {}
Menu(key)
song_key = input("输入下载歌曲名:")
Download(song_key)效果图

声明:吾爱破解论坛本人文章转载

没有回复内容